[179. 最大数](https://leetcode-cn.com/problems/largest-number/)
1 | class Solution { |
1 | class Solution { |
当全都升序的时候。只有最后一个元素是山峰。没有符合nums[i] > nums[i + 1]的
当全都降序的时候。第一个元素是山峰,直接返回。第一个元素符合nums[i] > nums[i + 1],后面的符合但是不是解,但是由于已经直接返回了,所以不会影响结果。
当中间有转折的时候。nums[i] > nums[i + 1]必定是符合的。
存不存在符合nums[i] > nums[i + 1]但是不是山峰的情况呢?只在全都降序时候第一个元素之后的存在。而这种情况上面说了对结果没有影响。总而言之就是只需要判断nums[i] > nums[i + 1]就可以了。
1 | class Solution { |
当nums[mid] > nums[mid + 1]时
这时候他处于一个递减子序列中,那么他的左边必定存在一个山峰,即使左边全是递减的,那么结果也会是左边的第一个元素。
如果他处于一个递增子序列,那么山峰一定会在他的右边。
如果恰好是lo和hi中间一块为单调,但lo和hi又不等于开头和结尾。
假设中间一块单调增加,如果之前的hi要到现在的hi,必定在那里存在一个山峰。
如果中间一块单调减少,如果之前的lo要到现在的lo,必定也在那里存在一个山峰。
1 | class Solution { |
逆波兰表达式:
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。 该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。 逆波兰表达式主要有以下两个优点:
去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。 适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/evaluate-reverse-polish-notation 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 | class Solution { |
根据答案意思,对于[x, y],区间,如果从x起步无法到达y之后的一个,则所有x和y区间内部的点起步都无法到达y的后一个点。但内部任意起点可以到达y和y之前加油站由此可以避开许多的起始点判定。
证明:
符合上述条件的区间中存在这样的关系 \[
\sum_{i=x}^{y}gas[i] < \sum_{i=x}^{y}cost[i]\newline
\sum_{i=x}^{j}gas[i] >= \sum_{i=x}^{j}cost[i]\ j \in [x, j) \newline
\] 第一个式子表明无法到达加油站y的下一个加油站,第二个式子表明从x出发可以到达 y以及y之前的所有加油站。
则对于区间中任意节点z \[ \sum_{i=z}^{y}gas[i]\newline = \sum_{i=x}^{y}gas[i] - \sum_{i=x}^{z - 1}gas[i]\newline < \sum_{i=x}^{y}cost[i] - \sum_{i=x}^{z - 1}gas[i]\newline < \sum_{i=x}^{y}cost[i] - \sum_{i=x}^{z - 1}cost[i]\newline = \sum_{i=z}^{y}cost[i] \]
1 | class Solution { |
1 | class Solution { |
1 | class Solution { |
写法二
1 | class Solution { |
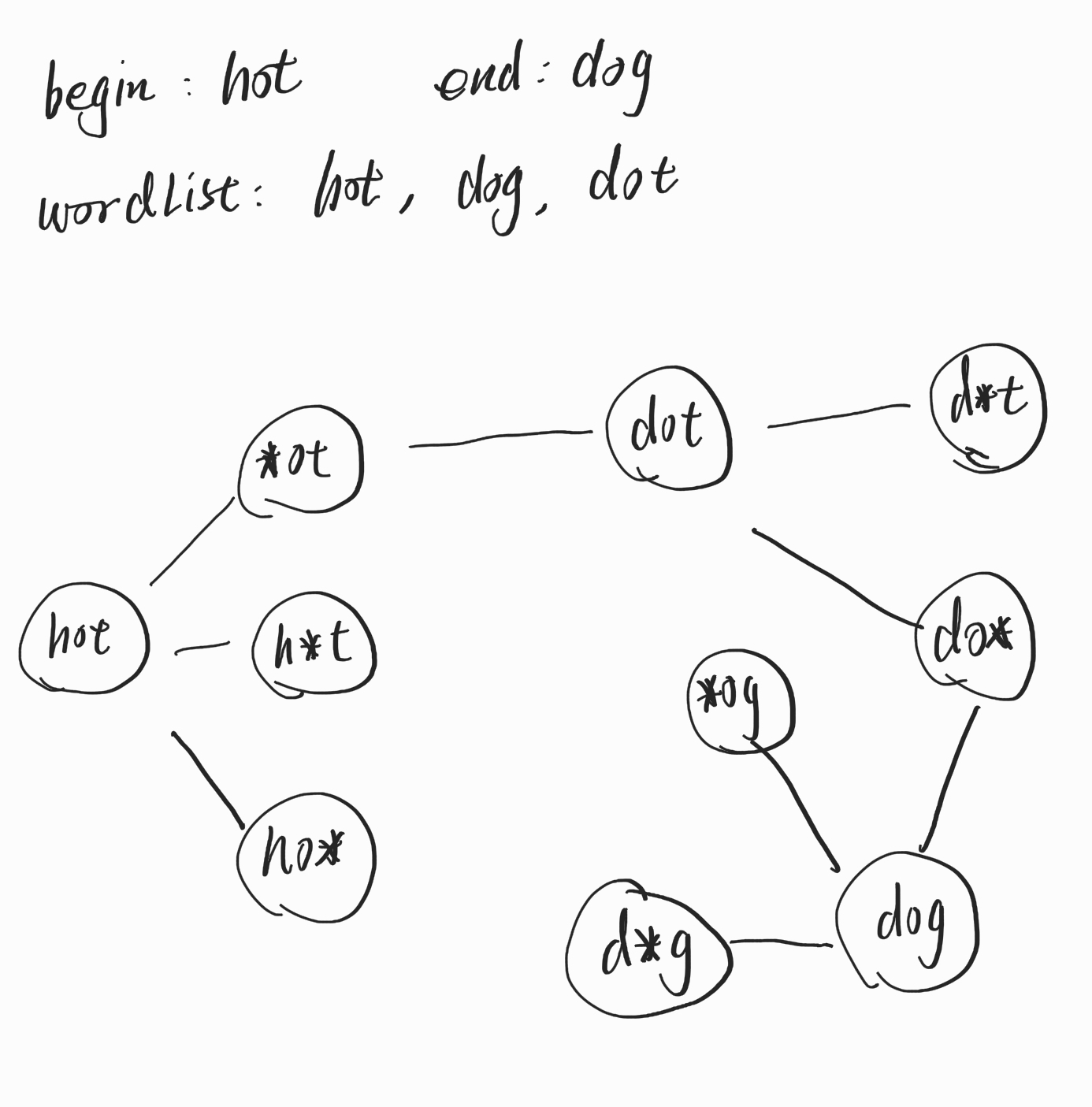
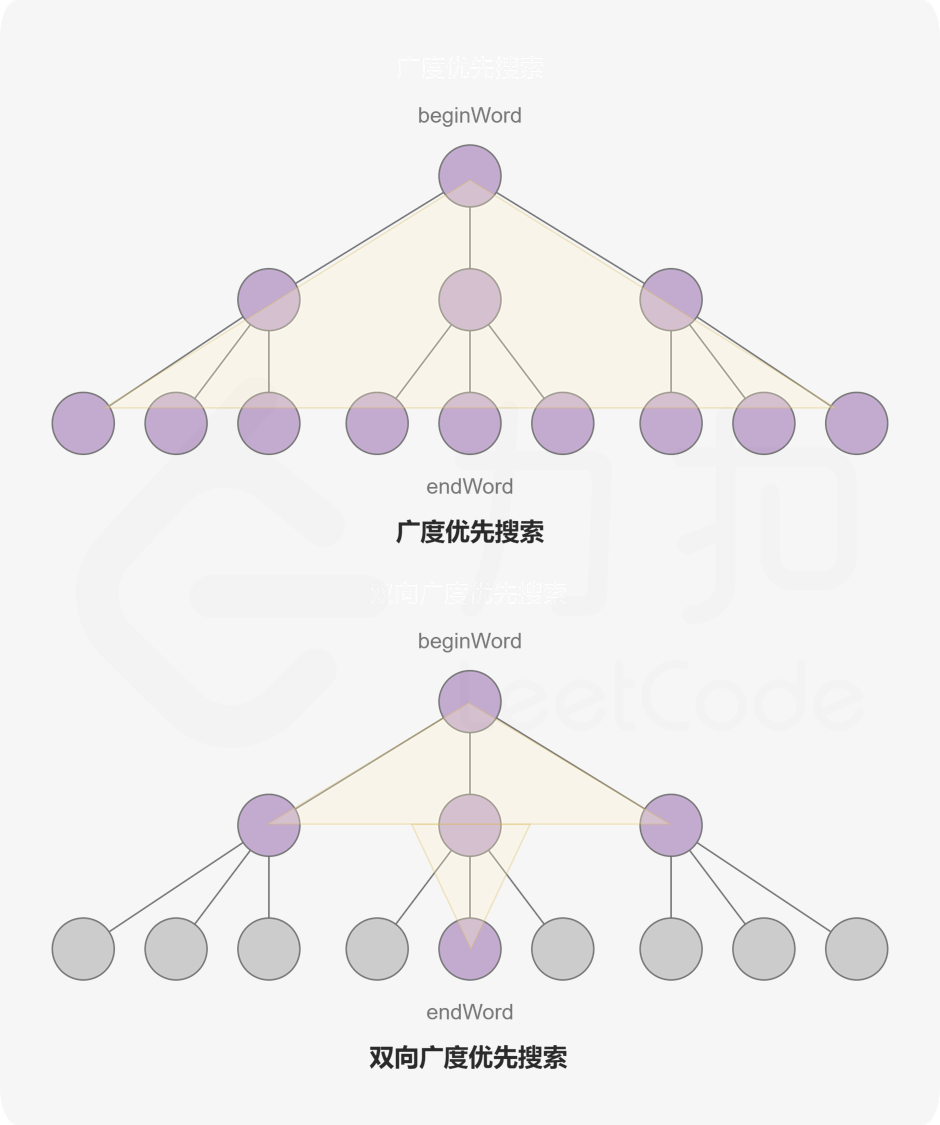
从begin和end同时开始,如果他们相遇了就是结果,这样可以减少许多分叉的占用
1 | class Solution { |
1 | 越界问题只要对除数是1和-1单独讨论就完事了啊 |
1 | 整理了一下思路,可以简单概括为: 60/8 = (60-32)/8 + 4 = (60-32-16)/8 + 2 + 4 = 1 + 2 + 4 = 7 |
溢出的情况只有负数最大除以-1会溢出,因为INT_MAX比INT_MIN绝对值小1
1 | class Solution { |
1 | class Solution { |
1 | class Solution { |
递归
递归栈需要O(n / k)的空间复杂度
1 | /** |
迭代
1 | /** |
穿针引线
1 | /** |
1 | class Solution { |
slot往前跑不可能跑的比ptA快,如果slot跑进A的原始领地,如果侵占了n个,那表示也用了n个A,所以A的指针永远在slot前
1 | class Solution { |