/** * Your MedianFinder object will be instantiated and called as such: * MedianFinder* obj = new MedianFinder(); * obj->addNum(num); * double param_2 = obj->findMedian(); */
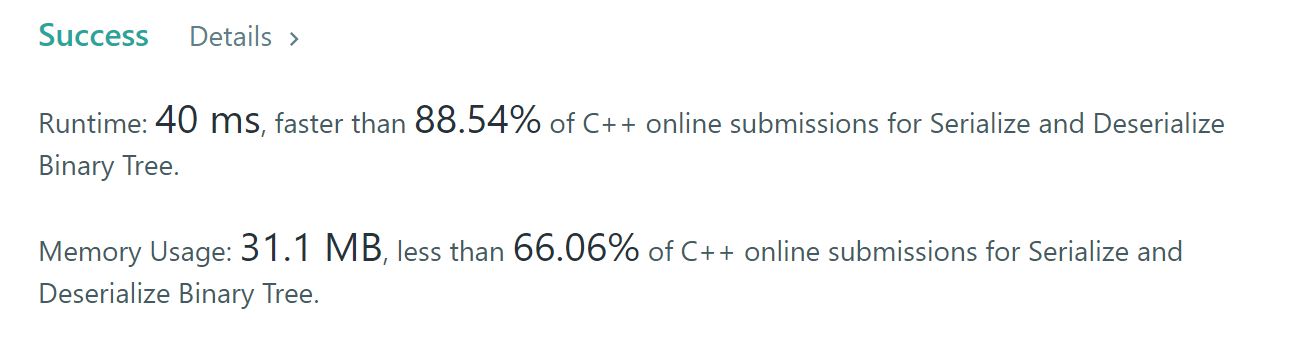
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode(int x) : val(x), left(NULL), right(NULL) {} * }; */ classCodec { public:
// Encodes a tree to a single string. stringserialize(TreeNode* root){ if(!root) return""; queue<TreeNode*> q; q.push(root); string ret; while(!q.empty()) { for(auto i = q.size(); i > 0; --i) { auto p = q.front(); q.pop(); if(!p) ret += "n "; else { ret += to_string(p->val) + " "; q.push(p->left); q.push(p->right); } } } ret.pop_back(); return ret; }
// Decodes your encoded data to tree. TreeNode* deserialize(string data){ if(data.empty()) returnnullptr; stringstreamss(data); string cur; getline(ss, cur, ' '); auto root = new TreeNode(stoi(cur)); queue<TreeNode*> q; q.push(root); while(!q.empty()) { for(auto i = q.size(); i > 0; --i) { auto p = q.front(); q.pop(); getline(ss, cur, ' '); if(cur[0] != 'n') { p->left = new TreeNode(stoi(cur)); q.push(p->left); } getline(ss, cur, ' '); if(cur[0] != 'n') { p->right = new TreeNode(stoi(cur)); q.push(p->right); } } } return root; } };
// Your Codec object will be instantiated and called as such: // Codec ser, deser; // TreeNode* ans = deser.deserialize(ser.serialize(root));
classSolution { public: inttrap(vector<int>& height){ int n = height.size(); vector<int> memo(n); int before = 0; for(int i = 0; i < n; ++i) memo[i] = before = max(before, height[i]); int ret = 0; int right = 0; for(int i = n - 1; i >= 0; --i) { right = max(height[i], right); ret += min(memo[i], right) - height[i]; } return ret; } };
双指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution { public: inttrap(vector<int>& height){ int left = 0, right = 0; int ret = 0; int i = 0, j = height.size() - 1; while(i < j) { left = max(left, height[i]); right = max(right, height[j]); if(left < right) ret += left - height[i++]; else ret += right - height[j--]; } return ret; } };

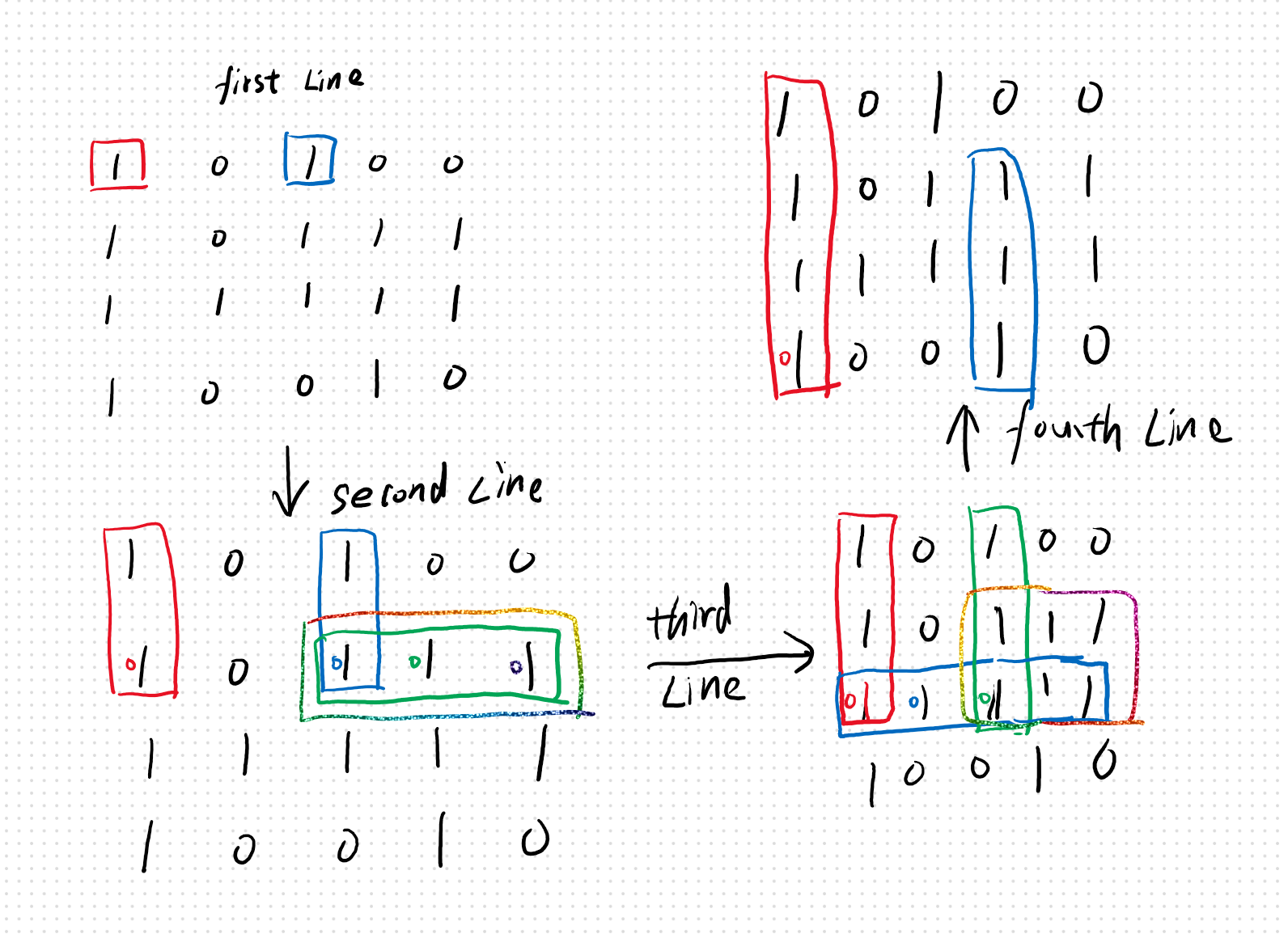
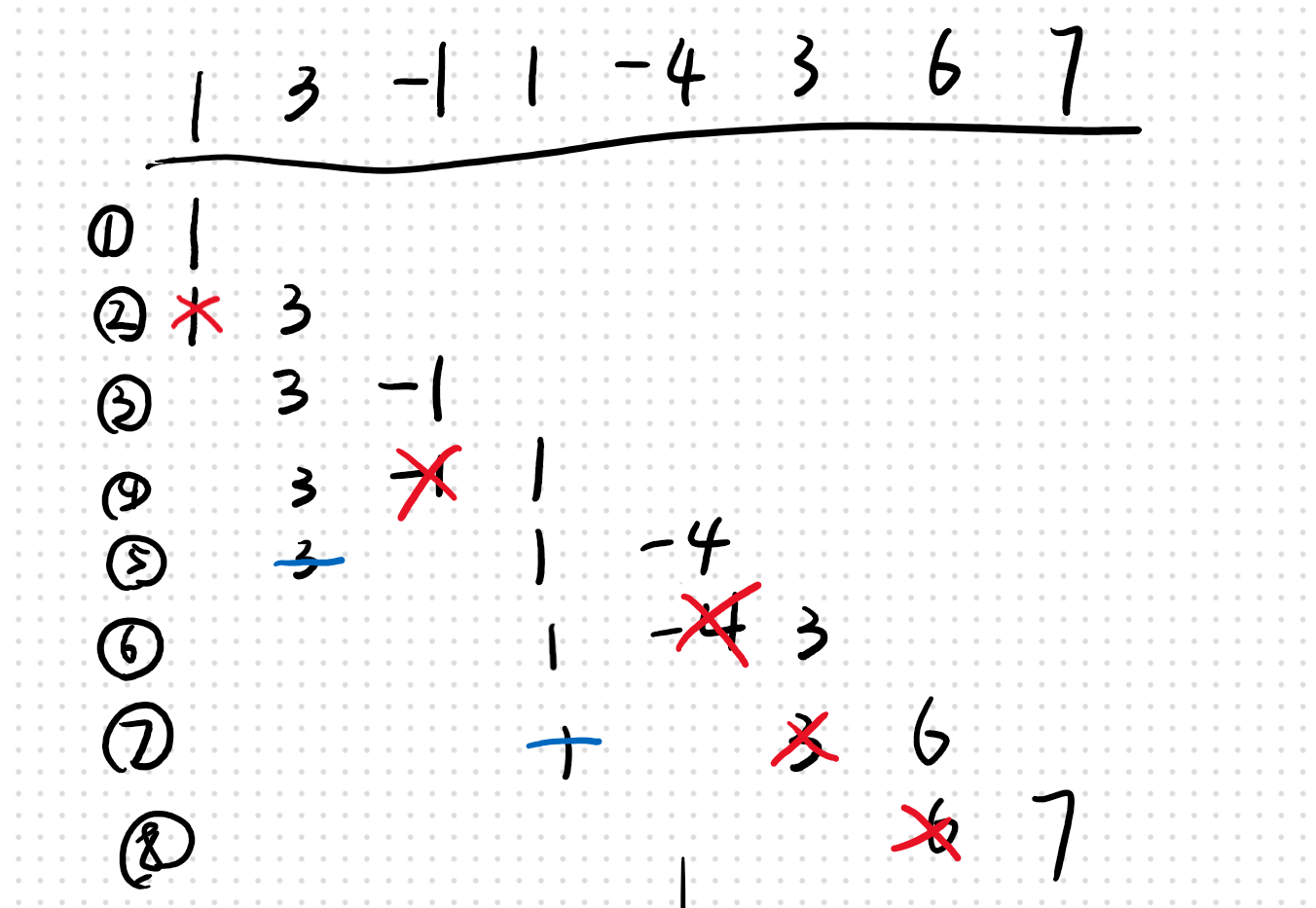
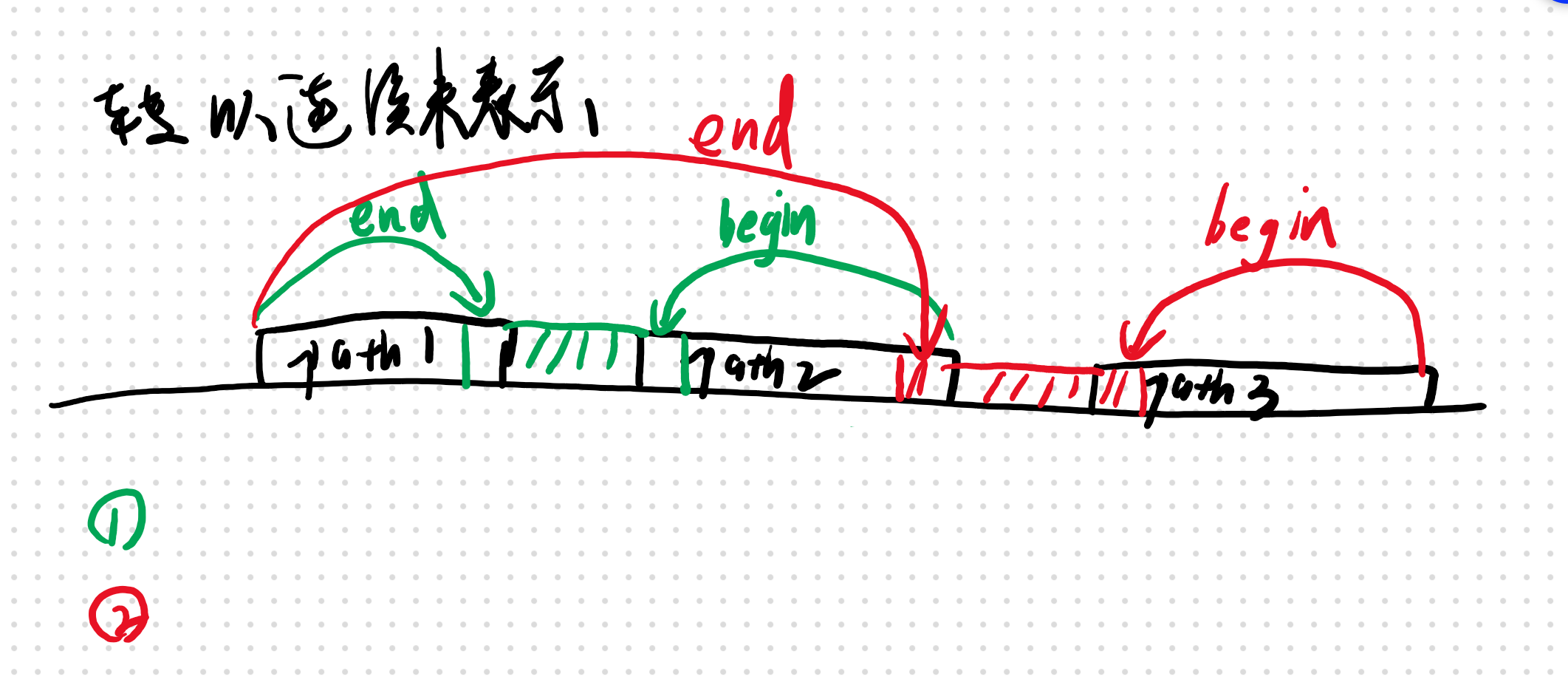
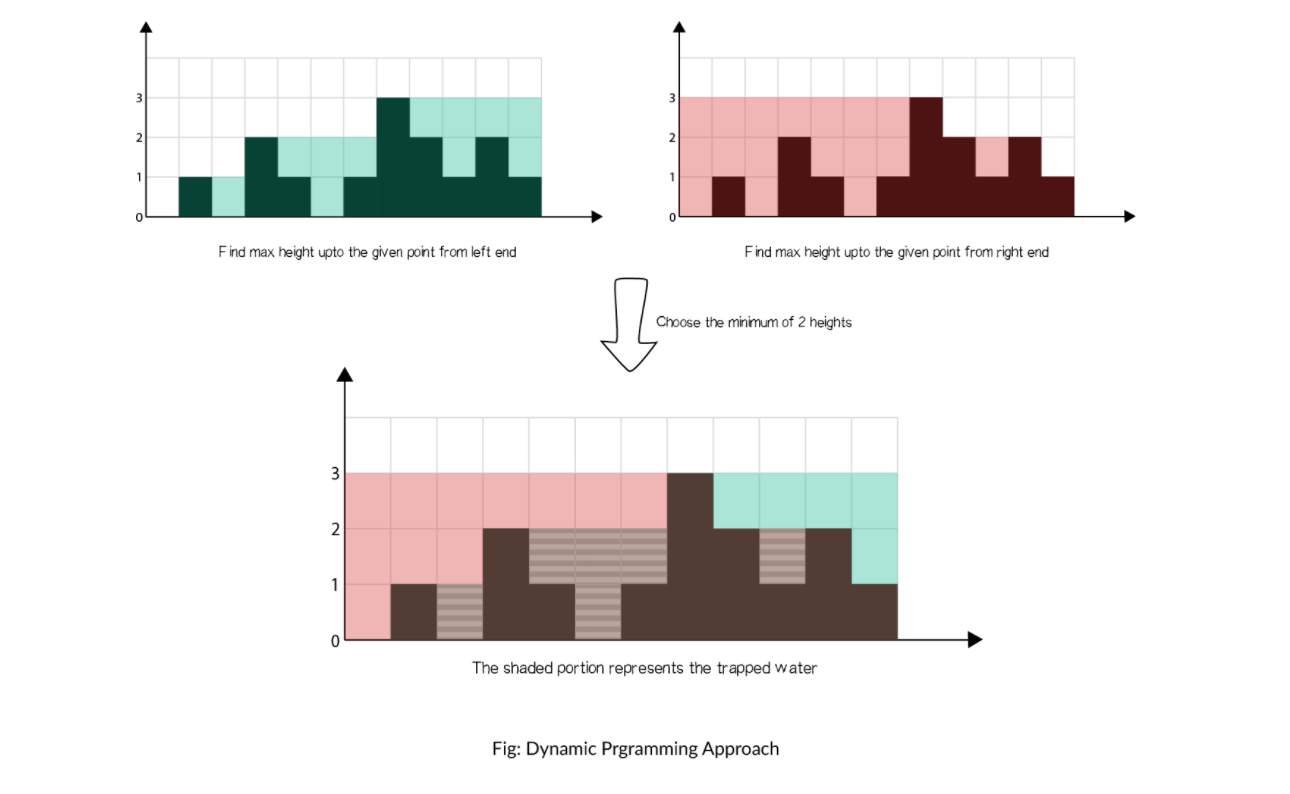 只可意会,左边由两边都是取得最低的量
只可意会,左边由两边都是取得最低的量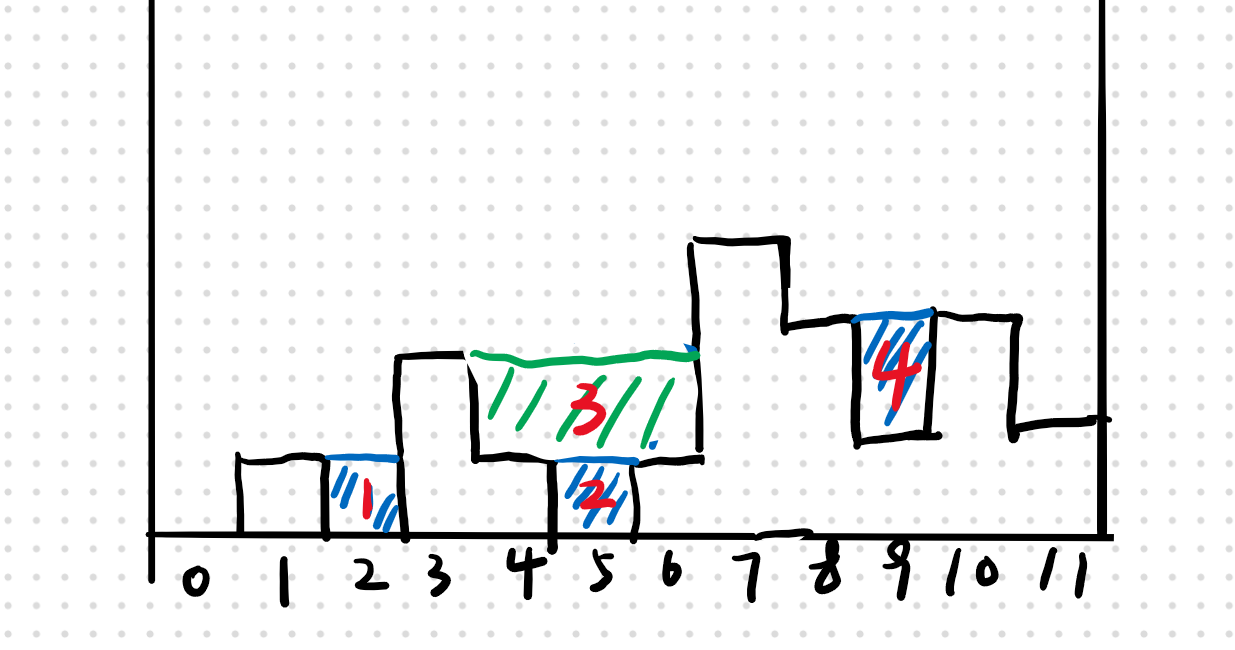 图中红色标号表示填充水块的次序
图中红色标号表示填充水块的次序