146. LRU Cache
1 | class LRUCache { |
使用doubleLinkedList是因为在删除时候需要操作前面的元素,因此DoublelinkedList可以实现O(1)的删除操作,而SingleLinkedList就需要O(n)
总体思路是访问过的移动到第一位,而最少访问的放在最后,如果新进来的时候缓存满了,那么就释放掉最后一位。
1 | class LRUCache { |
使用doubleLinkedList是因为在删除时候需要操作前面的元素,因此DoublelinkedList可以实现O(1)的删除操作,而SingleLinkedList就需要O(n)
总体思路是访问过的移动到第一位,而最少访问的放在最后,如果新进来的时候缓存满了,那么就释放掉最后一位。
1 | class Solution { |
1 | class Solution { |
Tips:usemid > x / mid instead of mid * mid > x, because of the overflow
1 | /** |
T(n) : O(nlogn)
总体是分成许多一半一半的,然后每一小部分merge
1 | /** |
1 | /** |
1 | class Solution { |
视为BFS问题
每个区域里都可以走到下一层的任何一个点,实在走不到了,只能换层了
1 | class Solution { |
review
1 | class Solution { |
1 | class Solution { |
o(n^2) 每次遍历过程中,当nums[j] < nums[i],意味着2者都不在其正确位置,若要得到正确排序,需要进行位置的交换,但此处不要求交换,因此将i标记为Unsorted Array的最底端,j标记为Unsorted Array的最顶端
1 | class Solution { |
O(nlogn)
排序后比较不同处的两个端点
1 | class Solution { |
1 | class Solution { |
1 | class Solution { |
将数组分为三部分NumsA, NumsB, NumsC
其中NumsA和NumsC是有序的,而NumsB是无序的
他们具有如下的规律,NumsA中的所有数字小于NumsB中的最小数字,而NumsC中的所有数字都大于NumsB中的最大数字
转换条件就是NumsB和NumsC中的最小值大于NumsA中的最大值,NumsA和NumsB中的最大值小于NumsC中的最小值 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class Solution {
public:
int findUnsortedSubarray(vector<int>& nums) {
int right = -1, left = -1;
int maxn = INT_MIN, minn = INT_MAX;
int n = nums.size();
// maxn记录NumsA和NumsB中的最大值,如果这个最大值比后面这个nums[i]大的话,说明不满足NumsA和NumsB中的最大值小于NumsC中的最小值
// 因此需要更新right为i,表示至少这个i是肯定不满足顺序的
// 如果都满足,就不断更新maxn为当前最大值,如果后面都是升序,那么right就不会变
// 因为需要获取左边部分的最大值,所以需要从左向右遍历
for(int i = 0; i < n; ++i)
{
if(maxn > nums[i])
right = i;
else
maxn = nums[i];
}
// minn记录NumsB和NumsC中的最小值,如果这个最小值比前面这个nums[i]小的话,说明不满足NumsB和NumsC中的最小值大于NumsA中的最大值
// 因此需要更新left为i,表示至少这个i是肯定不满足顺序的
// 如果都满足,就不断更新minn为当前最小值,如果后面都是降序,那么left就不会变
// 因为需要获取右边部分的最小值,所以需要从右向左遍历
for(int i = n - 1; i >= 0; --i)
{
if(minn < nums[i])
left = i;
else
minn = nums[i];
}
return right == -1 ? 0 : right - left + 1;
}
};
1 | class Solution { |
1 | class Solution { |
1 | class Solution { |
视频介绍:
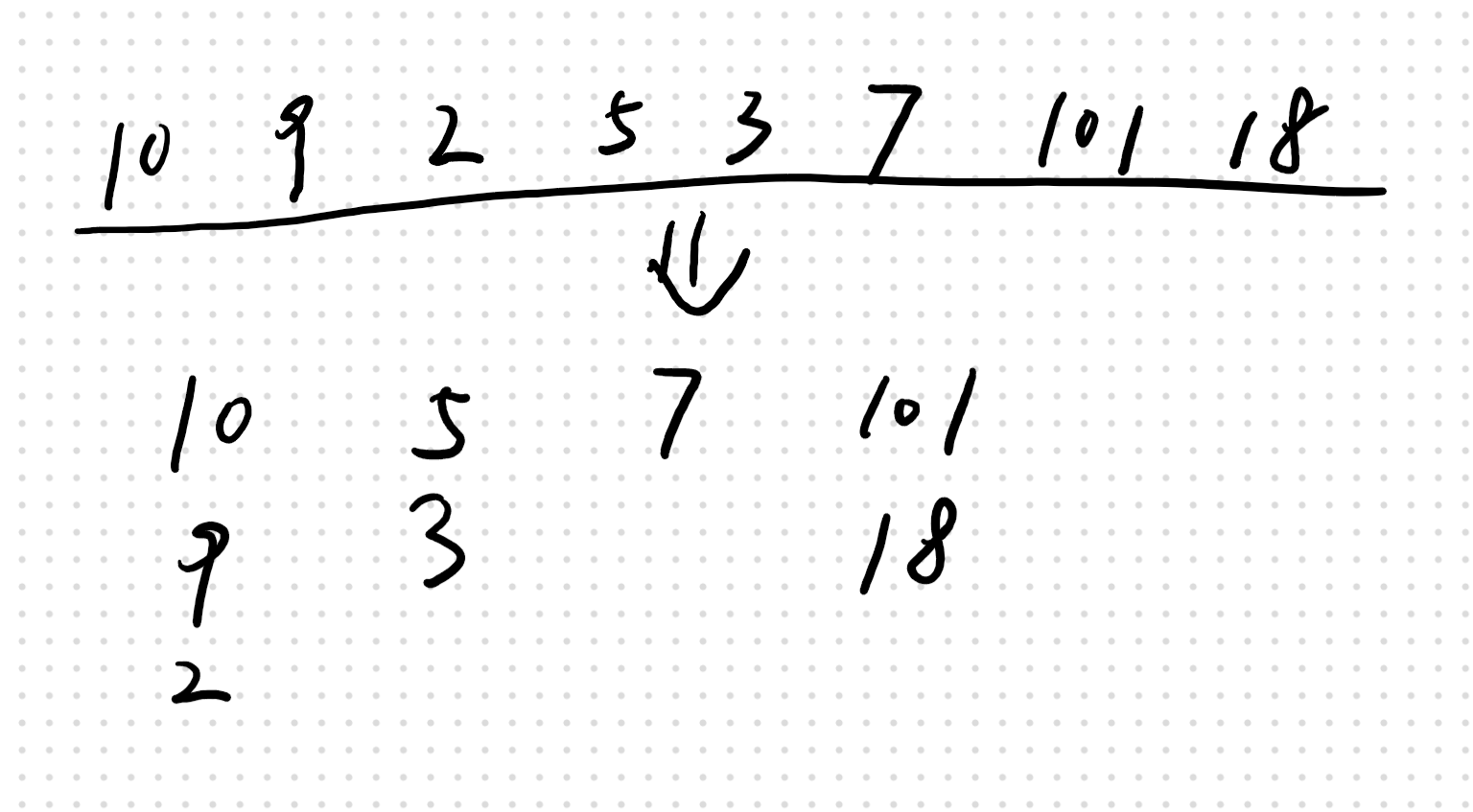 如图,把所有牌分堆,从左开始寻找,一旦找到他比某个牌堆的顶端少,就放过去,以贪婪原则。
如图,把所有牌分堆,从左开始寻找,一旦找到他比某个牌堆的顶端少,就放过去,以贪婪原则。
这样分出的排队数量就是里面的最长增长的串,保证这一点可以通过数学归纳法,详情见视频3:43, 直观的理解是因为:
每个排队中的顺序都是依据原数组中顺序递减的,因此,每个牌堆中最多只能取一张牌,因此增长序列长度<=牌堆数
1 | class Solution { |
1 | /* |
T(n) : O(n)
S(n) : O(n)
1 | /* |
T(n) : O(n)
S(n) : O(n)
1 | class Solution { |
若求是否存在两个子序列相等,只需要求序列中是否存在子序列和等于总序列的一半。所以当和为奇数时候就是无效的。
转化为dp
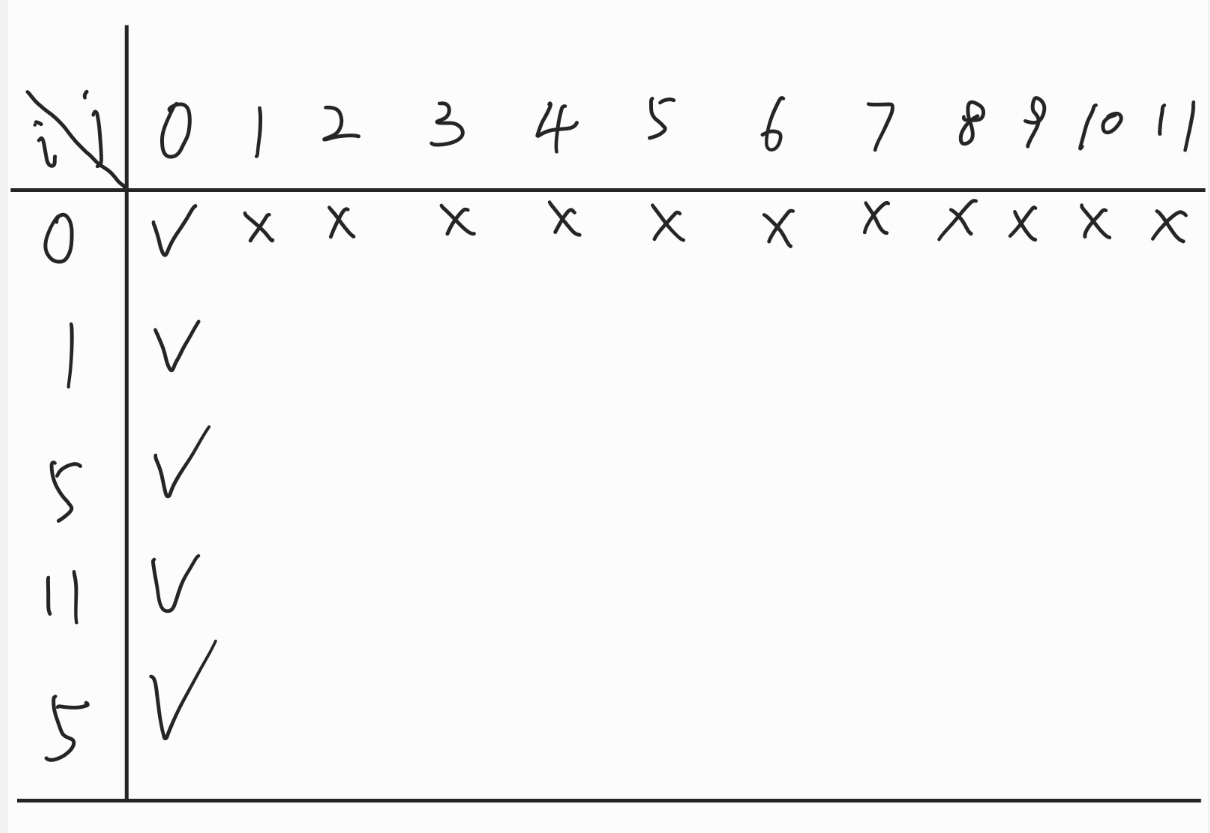
dp[i][j]表示0~i的数字能否获得和为j,若能为true,不能为false。
对于一行的dp[i][j]来说
nums[i],则如果0~i-1的数字可以达到j - nums[i]和的话就是true,反之为false。也就是dp[i - 1][j - nums[i]]是否为truenums[i - 1],则如果0~i-1可以达到和为j,也就是dp[i - 1][j]是否为true。基础情况是当没有数字时,当且仅当j为0时为true。当和为0时,对于所有数字都是true,因此只需要不取。
1 | class Solution { |
1 | class Solution { |
此处从sum走是因为,i - num是一个小于 i 的值,可以保证走在后面的时候这个值还是上一行生成的结果,如果从小到大走,走到后面时就会把前面的结果刷新掉了
review
1 | class Solution { |