114. Flatten Binary Tree to Linked List
我越来越菜了
1 | /** |
in-order 遍历就是从小到大的排序,因此只需要进行in-order遍历
中序遍历中先把最左边的加进栈,然后走一个节点的右边。当没有右树的就会进入下一个循环走到上一个树
inorder递归
1 | /** |
1 | /** |
in-order 遍历就是从小到大的排序,因此只需要进行in-order遍历
中序遍历中先把最左边的加进栈,然后走一个节点的右边。当没有右树的就会进入下一个循环走到上一个树
1 | /** |
1 | /** |
太强了
review
和上面区别就是他留了一部分左子树给后面处理,而我就直接处理完了
1 | /** |
由于括号是包裹的,后出现的左括号会匹配后面遇到的第一个右括号,所以使用堆栈
1 | class Solution { |
本质上就是将堆栈方法改为了函数递归栈实现,碰到]就返回,碰到[就进去
1 | class Solution { |
处理一个框框中的数据,框框里遇到框框就再递归
review
1 | class Solution { |
很绕,由于不能改数组,这种情况废弃
1 | class Solution { |
T(N) : O(nlogn)
S(n) : O(1)
设cnt为数组中小于等于当前元素的元素的个数,设当前mid为target
将重复的数字看作是插入到了数组中,当插入到了比target小的数中,那么设i < target,cnt[i]必然<i,当插入到了比target大的数中,设j > target,cnt[j]必然>j,因为多了一个比他小的cnt。
如果都正常的话,在1~target-1区间中的数cnt[i]==i,target~n中的数必然>j
由此,在1~n区间内进行二分
1 | class Solution { |
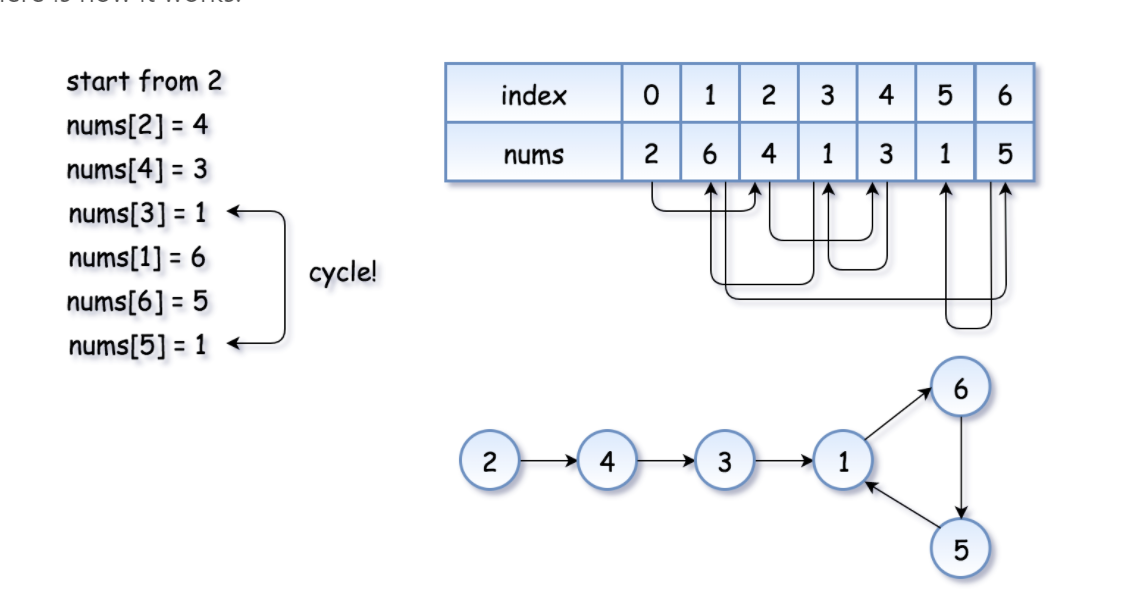
由于位于0处的数字不可能是0,所以他不可能原地跳不出去。 如果碰到一个原地跳不出去的,那就说明已经是环了
1 | class Solution { |
1 | class Solution { |
从后开始,对于温度为70的,接下来只会出现71~100的温度,只需要记录这些温度出现的天数,然后寻求一个最近的天数即可。由于是从后面开始更新的,所以不用怕前面的天数出来扰乱我
1 | class Solution { |
假设,对于位于i = 1处的天气为30度,若i = 2处的天气为50,而i = 4处的天气为30,显然,对于I = 1来说,i = 4是对他没有任何意义的,因此可以舍弃掉i = 4;
反之,若T[1] = 30, T[2] = 50, T[4] = 100, 则无法舍弃T[4] 因为若1和2之间出现一个60,则T[4]必须留着。
对于这种次序,只保留从大到小的序列,前面一个如果比后面大,后面的对于前面一个就无用了,就出栈,然后自己算完自己的后,入栈,一人就可以遮蔽后买你的所有效果
另一种堆栈 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
vector<int> ret(temperatures.size(), 0);
stack<int> s;
for(int i = 0; i < temperatures.size(); ++i)
{
while(!s.empty() && temperatures[i] > temperatures[s.top()])
{
auto tmp = s.top();
ret[tmp] = i - tmp;
s.pop();
}
s.push(i);
}
return ret;
}
};
1 | class Solution { |
先插入最高的人,最高的人组成的子序列所排列的顺序一定是由其K所决定的,当插入第二大的序列后,他不会影响第一大的序列,且仅仅由其本身和比他的序列影响,由其相对位置插入,可知,当为0时,就插到比他大的0前面,为1时,就插到比他大的1前面,比他大的那个往后移一位
结合explaination 最后一个人的位置不会影响前面的人,但前面人的位置将影响到最后一个人,因此最后一个人的k必定表示其绝对位置,将其划分为一堆的子问题,每个子问题在解决时都先忽略子问题中最小的的那个数,那个数在所有其他数排列完后再插入那个绝对的位置。 依此,则从最大数开始排起,后面插入的数对于先前的序列来说必定是插入其的K位置,不断扩大子问题,往复,直到整个序列往复。最小的数插入到其的K位置。1
2
3
4
5
6
7
8
9
10
11
12People are only counting (in their k-value) taller or equal-height others standing in front of them.
So a smallest person is completely irrelevant for all taller ones. And of all smallest people, the one
standing most in the back is even completely irrelevant for everybody
else. Nobody is counting that person. So we can first arrange everybody else,
ignoring that one person. And then just insert that person appropriately.
Now note that while this person is irrelevant for everybody else,
everybody else is relevant for this person - this person counts exactly everybody in front of them. So their count-value tells you exactly the index they must be standing.
So you can first solve the sub-problem with all but that one person and then just insert that person appropriately.
And you can solve that sub-problem the same way, first solving the sub-sub-problem with all but the last-smallest person of the subproblem.
And so on. The base case is when you have the sub-...-sub-problem of zero people. You're then inserting the people in the reverse order, i.e.,
that overall last-smallest person in the very end and thus the first-tallest person in the very beginning. That's what the above solution does, Sorting the people from the first-tallest to the last-smallest, and inserting them one by one as appropriate.
中心思想:最小的数的k必定表示其在结果中的绝对位置,抛开这个最小的数,生成一个子问题。再抛开子问题中最小的数,生成一个子-子问题......
针对[[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]问题
[7,0],[7,1]的问题,此时他们的k表示他们的绝对位置,由此排列即可。[7,0],[7,1],[6,1]时,很显然[6,1]对[7,0],[7,1]不会有任何干扰,但[7,0],[7,1]对他具有干扰, 因为此时他最小,所以所有人和他相关,最小的数字的k必然表示他的绝对位置,前面有一个比他大,所以插到第一个的后面,也就是第二个的前面。所以直接把他插入到1的位置上,这时候序列就是[7,0],[6,1], [7,1]1 | class Solution { |
1 | class Solution { |
1 | class Solution { |
右移加上最后一位,类似动态规划的思想
1 | class Solution { |
每走到一步就判断他的最后一位,差不多就寻求一个最大区间
两步: 1. 保持原顺序 2. 零在最后面
总体思路
先实现1后实现2,需要认识到如下之点
The 2 requirements of the question are:
Move all the 0's to the end of array.
All the non-zero elements must retain their original order.
It's good to realize here that both the requirements are mutually exclusive, i.e., you can solve the individual sub-problems and then combine them for the final solution.
1 | class Solution { |
T(n) : O(n)
S(n) : O(n)
1 | class Solution { |
T(n) : O(n) S(n) : O(1)
1 | class Solution { |
T(n) : O(n)
S(n) : O(1)
这里仅需要执行非0的个数
由于noZeroIndex和num不同时,noZeroIndex指向的必定是0元素,这时与num进行交换就可以将0元素移动到后头,依次往复,所有的0都会跑到后面去
因为如果是0,noZeroIndex就不会加,就会留着,如果相同,那就是自己加自己。
1 | /** |
1 | /** |